I Built HelloBible's Voice of Customer Pipeline for ~$2 a Month.
4 scattered feedback channels (Zendesk, WhatsApp, Play Store, App Store) - 2,020 customer verbatims classified across 27 business-specific themes - for ~$2 in API calls. Built with Python and Claude Haiku. Runs monthly from a single command, with checkpoints so an interruption doesn't cost a re-run.
Context. Customer feedback at HelloBible was scattered across four channels with no consolidation, no taxonomy, no shared language for the team to talk about users. Decisions on bugs, features, and churn risk were getting made on vibes. I built the pipeline that fixes it.
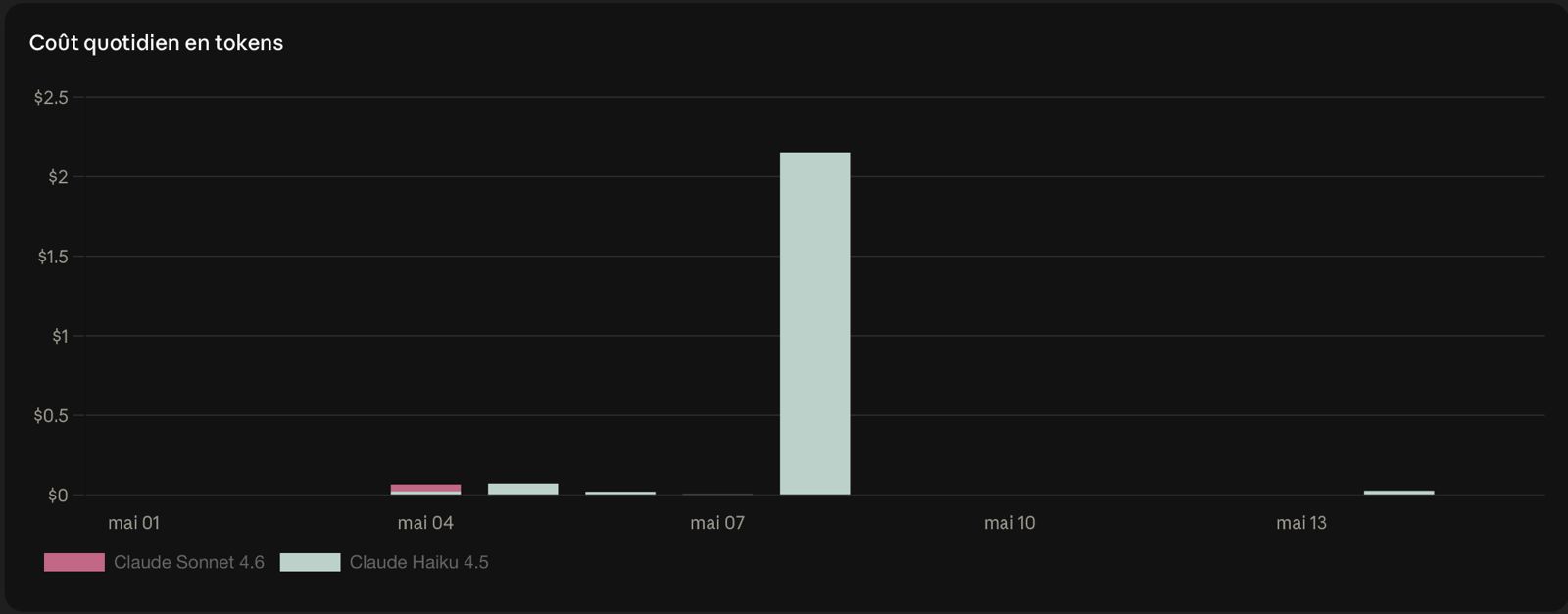
Result. 2,020 verbatims classified for 2026. One CSV for the team to explore, one Markdown synthesis for the CEO. ~$2 in API costs. Pipeline runs monthly from a single Python command, resumable, with checkpoints every 100 records.
HelloBible had no reliable way to compare recurring bugs, feature requests, and churn-risk signals across channels. Which bugs are recurring? What do users actually want next? Who’s threatening to churn? Nobody could tell you without spending half a day in raw text - so people stopped checking.
The pipeline centralises and classifies feedback from the 4 channels monthly. 2,020 verbatims classified across 27 business-specific themes, for ~$2 in API costs. I deliver one monthly CSV and one CEO readout, both fed by what users actually say rather than what’s top-of-mind in the last meeting.
The friction I found
HelloBible had feedback flowing in from 4 places, none of which talked to each other:
- Zendesk support tickets (1,145 in 2026)
- WhatsApp beta group (516 messages, 8 months of scrolling history)
- Google Play Store reviews (326)
- App Store iOS reviews (33 from 2026 out of 118 pasted manually)
Tickets got read one by one. Store reviews were checked in each app’s interface. The WhatsApp group was scrolled manually when someone remembered to. No taxonomy, no priority signals, no shared way for the team to talk about users.
The decisions that depended on this data were getting made on intuition. Which bugs are recurring? What features do users actually want? Who’s threatening to churn? Nobody could tell you without spending half a day in raw text.
What I actually built
A 6-step Python pipeline that runs monthly:
- Export Zendesk via the Incremental API (full tickets + every comment in every conversation)
- Parse the WhatsApp
_chat.txtexport (with a robust regex that handles names containing colons - my first version broke on something like ”~ Jean 3:16”) - Integrate monthly Google Play Store CSVs (with UTF-16 BOM handling because of course they ship it that way)
- Append App Store iOS reviews (manually copy-pasted, because there’s no public reviews API for iOS)
- Classify every verbatim via Claude Haiku 4.5 against a 27-theme taxonomy I designed and iterated
- Output two artifacts: a CSV for the team to explore and filter, a Markdown executive synthesis for the CEO
The whole thing runs from a single command. State is checkpointed every 100 records, so a failed run resumes from where it stopped instead of forcing a full reclassification.
How it costs ~$2 a month
Pipeline design choices that keep the cost down:
- Deterministic pre-filter on message length and content type (saves ~14% of LLM calls)
- Claude Haiku 4.5 for bulk classification, not a larger model
- Ephemeral cache on the taxonomy system prompt (amortized across all calls)
- Checkpointing every 100 records (a crash doesn’t re-run already-classified records)
Total cost for 1,703 classifications: ~$2 in API calls. The technical details are in the accordion below.
The technical architecture
Stack
- Python 3 with
anthropic,requests,csv,json,re,pathlib - Zendesk Incremental Export API for tickets + Comments API for full conversations
- Anthropic Messages API with
claude-haiku-4-5-20251001andcache_control: {"type": "ephemeral"}on the system prompt - JSONL as intermediate format (append-friendly, diffable, debuggable)
- CSV UTF-8-sig for Google Sheets compatibility
- Markdown for the executive synthesis
- Local execution - scripts in iCloud, outputs in
~/Downloads/
Flow end-to-end
1. export_zendesk_2026.py → zendesk_tickets_2026.jsonl (1,145 tickets)
2. consolidate_voc_2026.py → voc_unified_2026.jsonl (2,020 verbatims)
3. classify_voc_haiku.py → voc_classified_2026.jsonl (theme + sentiment + signal)
4. [dedup + export CSV] → voc_classified_2026_final.csv (Google Sheets)
5. [executive synthesis] → VoC_HelloBible_2026.md (CEO read)
6. run_monthly_voc.py → orchestrates 1-5 every month
The taxonomy
27 themes with hierarchical prefixes for rollups (bug.*, contenu.*, abonnement.*, etc.). Plus 4 sentiments, 7 signals, and a confidence field on every classification.
Some entries that show the domain encoding:
abonnement.paiement_localfor Wave / Orange Money - African market payment friction that generic taxonomies misscontenu.ia_qualite(factual AI errors) vscontenu.theologie(doctrinal disagreements) - a subtle but important distinction for an app that generates AI Bible contentchurn_riskdefined precisely as “the user threatens or announces leaving / unsubscribing”- “Mise en garde théologique” flagged separately because “the app replacing God” is a specific ethical churn risk that generic AI taxonomies miss entirely
I didn’t let the LLM “discover” the categories. The taxonomy is the product - it’s what becomes the team’s shared language for talking about users.
Cost engineering specifics
- Deterministic pre-filter saves ~14% of LLM calls for free
- Haiku at ~$0.80/M input + $4/M output tokens
- Ephemeral cache amortizes the ~1.5kb taxonomy system prompt across all calls
- Total cost: ~$2 for 1,703 classified records
Safety and idempotence
- Strict JSON validation on Haiku output → unknown theme falls back to
bruit - Exponential retry (5 attempts, 5s → 60s backoff) on rate limits
- Graceful fallback: if all retries fail, the record is saved with
filter_reason: "classification_failed"- never silent data loss - Checkpoints every 100 records (resumable state on disk)
- Append-mode on all outputs (no data loss after interruption)
- Self-deduplication post-hoc (a partial-stats bug introduced 51 duplicates on first run)
What broke (the useful ones)
The bugs worth telling about - not the typos, the ones that taught me something:
- WhatsApp regex broken on colons in names like ”~ Jean 3:16”. The first split on
:captured the Bible reference as the message body. Fix: split on the first": "pattern instead. - Haiku appending text after the JSON object caused
json.loadsto fail with “Extra data”. Fix: regex-extract the first JSON object instead of parsing the whole response. - Hit the monthly Anthropic API limit at record 650/1,703 mid-classification. Bumped the limit, the script resumed from the checkpoint. The resumable design worked as intended.
- Partial stats + 51 duplicates after resume because the stats dict reset on each run. Claude Opus was used to audit classification consistency and flagged that my numbers didn’t add up arithmetically. Regenerated a clean deduplicated CSV.
What this changes operationally
Before the pipeline, deciding what to build next at HelloBible relied on individual memory and whatever feedback was freshest. Now the team has the data to answer three concrete questions every month:
- What’s bothering users right now? (filter the CSV by
sentiment: negativeand recurring themes) - What do users actually want next? (filter by
signal: feature_requestand roll up by theme) - Who’s about to leave? (filter by
signal: churn_riskand surface in support)
The exec gets a 1-page Markdown synthesis. The product team gets the full CSV to dig into. Same data, two artifacts, ~$2 a month to keep both fresh.
The taxonomy standardised how recurring issues and requests are categorized internally. The pipeline refreshes it every month from a single Python command.
Want to talk about something like this?
Email me, send a LinkedIn message, or download the CV. Conversations are what this site is built for.